




DeepSeek 低调发布 V3-0324:性能比肩 Claude 3.5
转载自《AI范儿》

昨晚,DeepSeek发布了备受期待的V3-0324模型,作为其V3系列的一次重要更新。这一版本在保持原有技术框架的基础上,针对性能、用户体验和实用性进行了显著优化,不仅进一步巩固了DeepSeek在开源AI领域的地位,也为开发者、研究者和普通用户提供了更强大的工具。本文将全面介绍DeepSeek V3-0324的主要特点、更新亮点及其潜在应用价值。
一、技术背景与架构延续
DeepSeek V3-0324延续了V3系列的核心架构,即基于混合专家(MoE)模型设计。据悉,该模型拥有6710亿个总参数,每次推理激活其中的370亿参数,兼顾了计算效率与输出质量。
此外,V3系列引入的多token预测(MTP)和无辅助损失负载均衡策略可能也在新版本中得到了进一步优化,尽管官方尚未公布具体的架构调整细节。模型总大小约为685GB(包括671亿参数的主模型和14亿参数的MTP模块),在Hugging Face上以MIT许可证开源,极大降低了社区使用和二次开发的门槛。
值得一提的是,尽管DeepSeek官方将此次更新定位为“小型升级”,用户和测试者的反馈却显示其改进幅度超出预期,尤其在编程、数学推理和创造性任务上的表现令人眼前一亮。
二、主要更新亮点
1. 性能提升:从编程到数学的全方位优化
V3-0324在多个关键领域展现了显著的性能进步:
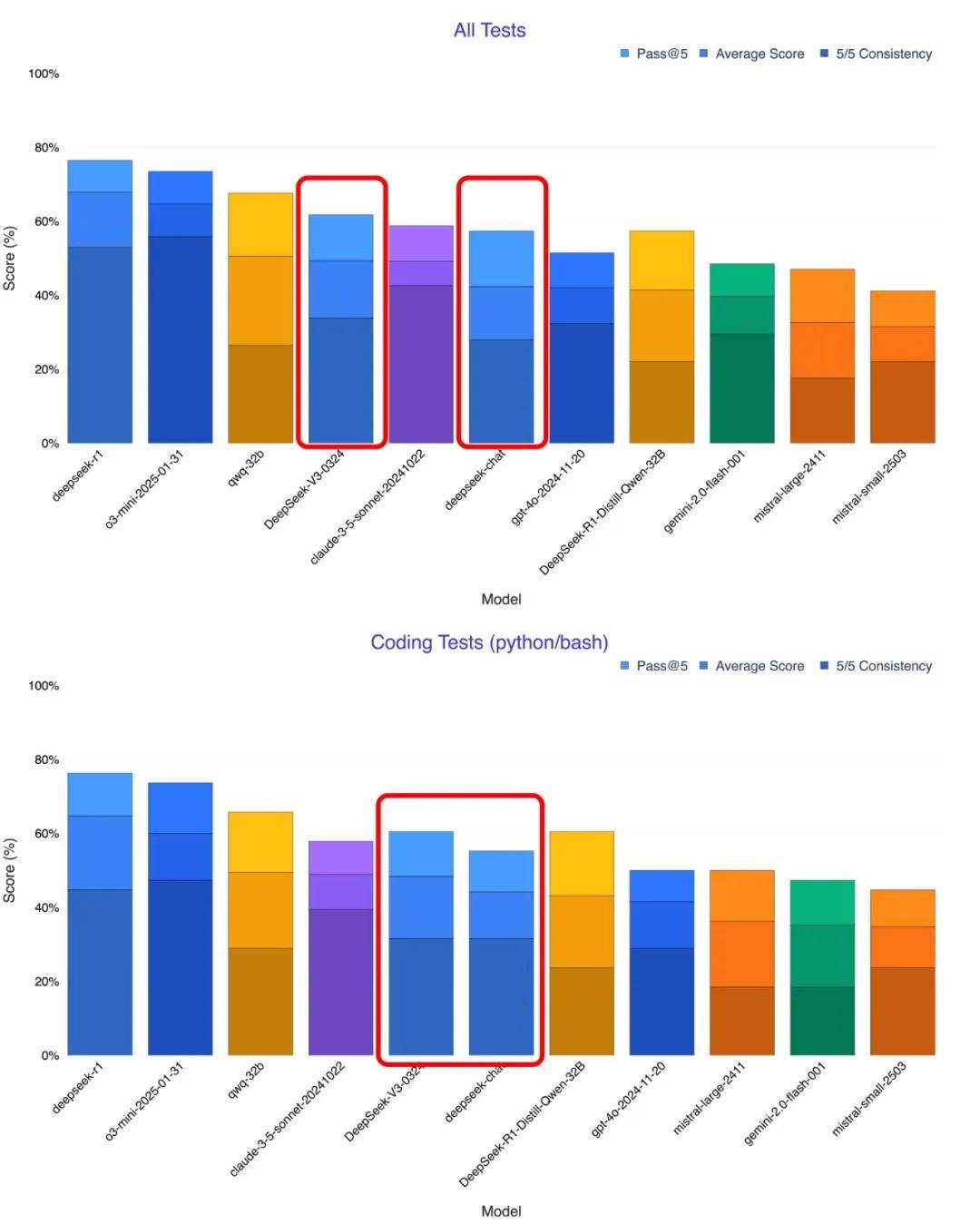
- 编码能力:用户测试表明,新模型在生成复杂代码(如700行无错误代码)时表现出极高的稳定性,接近甚至部分超越了Claude 3.5的水平。这一特性使其在软件开发、自动化脚本编写等场景中极具竞争力。
展开全文
- 数学推理:相较于V3,V3-0324在数学问题求解上的表现更加出色,可能得益于训练数据的优化或推理策略的微调,为需要高精度计算的用户提供了可靠支持。
- 创造性输出:在前端设计任务中(如生成SVG图像或海报设计),模型展现出更强的视觉创意能力,输出结果更符合实际需求。
2. 用户体验优化:更简洁、更高效
DeepSeek此次更新注重提升交互的便捷性:
- 默认关闭“深度思考”模式:这一调整减少了不必要的复杂流程,使模型响应更迅速,适合快速迭代的任务。
- API稳定性:接口和调用方式与V3保持一致(model='deepseek-chat'),开发者无需修改现有代码即可无缝切换至新版本。
- 多平台支持:用户可通过DeepSeek官网、移动应用、API或第三方平台(如OpenRouter)访问模型,覆盖多种使用场景。
3. 开源与社区赋能
V3-0324不仅延续了DeepSeek一贯的开源传统,还采用了更宽松的MIT许可证。这意味着研究人员和开发者可以自由下载、修改和部署模型,极大地推动了AI技术的普及和创新。模型在Hugging Face上的公开访问也为全球用户提供了便利。
4. 输出风格微调
有用户注意到,V3-0324的输出语气相较于V3更偏向技术化和正式化。虽然这可能使其在某些对话场景中略显“冷淡”,但在专业性要求较高的任务中,这一变化反而提升了实用性。
三、应用场景与实际价值
DeepSeek V3-0324的多方位优化使其适用于广泛的应用场景:
- 软件开发:强大的编码能力可助力开发者快速生成高质量代码,提升开发效率。
- 学术研究:优化的数学推理和开源特性使其成为研究人员探索AI算法和解决复杂问题的理想工具。
- 创意设计:前端设计能力的提升为设计师提供了更多灵感来源,尤其在快速原型制作中表现出色。
- 教育与培训:模型的高精度输出和易用性使其适合用于编程教学、数学辅导等领域。
四、社区反响与未来期待
自发布以来,V3-0324在社区中引发了热烈讨论。尽管官方未提供详细的技术报告或基准数据,来自X帖子和用户评测的初步反馈普遍积极。许多人认为其性能提升远超“小型升级”的预期,甚至有声音将其与顶级闭源模型相提并论。然而,输出风格的变化也引发了一些争议,部分用户怀念V3更人性化的语气。
未来,随着更多独立测试的展开,V3-0324的具体能力和局限性将进一步明朗。DeepSeek是否会在后续版本中平衡技术性与对话自然度,或进一步扩展模型的应用边界,值得持续关注。
五、结语
DeepSeek V3-0324以性能提升、用户体验优化和开源赋能为核心,展现了其在AI领域的雄心与实力。对于追求高效编程、精准计算或创意输出的用户而言,这款模型无疑是一个值得尝试的强大工具。作为V3系列的延续,V3-0324不仅巩固了DeepSeek的技术优势,也为开源AI社区注入了新的活力。在人工智能飞速发展的2025年,这款模型的发布标志着DeepSeek迈向更高目标的重要一步。
© AI范儿








评论